


The History of AI in 7 Experiments
The breakthroughs, surprises, and failures that brought us to today.

Brought to you by Vanta
Growing a business? Need a SOC 2 ASAP?
Vanta, the leader in automated compliance, is running a one-of-a-kind program for select companies where we'll work closely with you to get your SOC 2 Type I in JUST TWO WEEKS.
Companies that qualify to participate will get a SOC 2 Type I report that will last for a year. This can help you close more deals, hit your revenue targets, and start laying a foundation of security best practices.
Due to the white glove support offered in this pilot, spots are limited. Complete the form to learn more and see if you qualify.
Actionable insights
If you only have a few minutes to spare, here’s what investors, operators, and founders should know about AI’s history.
Architecting logic. In the summer of 1956, Herbert Simon and Allen Newell showed off their remarkable program “Logic Theorist” to a collection of enlightened peers, only to be met with indifference. In the years since, Logic Theorist – which was capable of proving complex mathematical theorems – has been recognized as the first functional AI program. Its use of structured, deductive logic was an example of “symbolic AI,” an approach that dominated in the following decades.
The rules of the world. AI’s most glorious failure may be a project named “Cyc.” In 1984, Douglas Lenat began his attempt to create a program with an understanding of our world. The then-Stanford professor sought to develop this context by inputting millions of rules and assertions the AI could use to reason – including basics like “all plants are trees.” Lenat believed insufficient knowledge represented a huge barrier for AIs that was best solved with thoughtful, manual intervention. Despite decades of development and hundreds of millions in investment, Cyc has struggled to deliver meaningful results.
Embodied AI. In the 1980s, a new school of practitioners emerged to challenge AI’s dogma. This group, led by Australian academic Rodney Brooks, argued that real intelligence wouldn’t come from assiduously designed logical frameworks but by allowing machines to take in sensory input and learn from their environment. This “embodied” approach to AI ushered in practical robots, albeit with narrow applications.
Emulating the brain. Geoff Hinton is regularly cited as the “godfather” of modern AI. The University of Toronto professor earned that honorific through his steadfast belief that powerful intelligence would be achieved by modeling the patterns of the brain. Hinton’s contributions to “neural networks” – a structure directly based on our gray matter – paved the way for modern AI systems to flourish.
Learning by doing. How do you create an AI capable of beating the world’s greatest Go player? In the mid-2010s, Cambridge startup DeepMind showcased the potential of a radically new learning technique called “reinforcement learning.” Rather than learning how to play chess or Go through a set of strict rules, DeepMind’s engines developed by playing the game and receiving positive or negative feedback on their actions. This methodology has driven advancements far beyond the Go board.
In their classic work, The Lessons of History, husband and wife Will and Ariel Durant analyzed the story of human civilization. Among their pithy and profound observations is this meditation: “The present is the past rolled up for action, and the past is the present unrolled for understanding.”
No aspect of our present moment feels more ready to act upon the fabric of our lives quite as radically as artificial intelligence. The technology is accelerating at a pace that is hard to comprehend. A year ago, crowd-sourced predictions estimated artificial general intelligence would arrive in 2045; today, it’s pegged at 2031. In less than a decade, we could find ourselves competing and collaborating with an intelligence superior to us in practically every way. Though some in the industry perceive it as scaremongering, it is little wonder that a swathe of academia has called for an industry-wide “pause” in developing the most powerful AI models.
To understand how we have reached this juncture and where AI may take us in the coming years, we need to unroll our present and look at the past. In today’s piece, we’ll seek to understand the history of AI through seven experiments. In doing so, we’ll discuss the innovations and failures, false starts and breakthroughs that have defined this wild effort to create discarnate intelligence.
Before we begin, a few caveats are worth mentioning. First, we use the term “experiments” loosely. For our purposes, an academic paper, novel program, or whirling robot fit this definition. Second, this history assumes little to no prior knowledge of AI. As a result, technical explanations are sketched, not finely wrought; there are no equations here. Thirdly, and most importantly, this is a limited chronicle, by design. All history is a distillation, and this piece is especially so. Great moments of genius and ambition exist beyond our choices.
One final note: This piece is the first installment in a mini-series on the foundations and state of modern AI that we’ll add to in the weeks and months to come. We plan to cover the field’s origins and technologies, and explore its most powerful companies and executives. If there are others you think would enjoy this journey, please share this piece with them.
Experiment 1: Logic Theorist (1955)
A mile from the Connecticut River’s banks, congregational minister Eleazar Wheelock founded Dartmouth in 1769. It is an august if modestly-sized university located in the town of Hanover, New Hampshire. “It is, Sir, as I have said, a small college, and yet there are those who love it,” famed 19th orator and senator Daniel Webster is supposed to have said of his alma mater.
Nearly two hundred years after the center of learning settled on a piece of uneven land optimistically named “the Plain,” it hosted a selection of academics engaged in a task Wheelock might have found sacrilegious. (Who dares compete with the divine to create such complex machines?) In 1956, John McCarthy – then assistant professor of mathematics – convened a 12-week workshop on “artificial intelligence.” Its goal was nothing less than divining how to create intelligent machines.
McCarthy’s expectations were high: “An attempt will be made to find how to make machines use language, form abstractions and concepts, solve kinds of problems now reserved for humans,” he had written in his grant application. “We think that a significant advance can be made in one or more of these problems if a carefully selected group of scientists work on it together for a summer.” That exclusive group included luminaries like Claude Shannon, Marvin Minsky, Nat Rochester, and Ray Solomonoff.
For a field so often defined by its disagreements and divergences, it is fitting that even the name of the conference attracted controversy. In the years before McCarthy’s session, academics had used a slew of terminology to describe the emerging field, including “cybernetics,” “automata,” and “thinking machines.” McCarthy selected his name for its neutrality; it has stuck ever since.
While the summer might not have lived up to McCarthy’s lofty expectations, it contributed more than nomenclature to the field. Allen Newell and Herbert Simon, employees of the think-tank RAND, unveiled an innovation that attained legendary status in the years that followed. Funnily enough, attendees largely ignored it at the time – both because of Newell and Simon’s purported arrogance and their tendency to focus on the psychological ramifications their innovation suggested, rather than its technological importance.

Just a few months earlier, in the winter of 1955, Newell and Simon – along with RAND colleague Cliff Shaw – devised a program capable of proving complex mathematical theorems. “Logic Theorist” was designed to work as many believed the human mind did: following rules and deductive logic. In that respect, Logic Theorist represented the first example of AI’s “symbolic” school, defined by this adherence to structured rationality.
Logic Theorist operated by exploring a “search tree” – essentially a branching framework of possible outcomes, using heuristics to hone in on the most promising routes. This methodology successfully proved 38 of the 52 theorems outlined in a chapter of Bertrand Russell and Alfred North Whitehead’s Principia Mathematica. When Logic Theorist’s inventors shared the capabilities of their program with Russell, particularly noting how it had improved upon one of his theorems, he is said to have “responded with delight.”
Though overlooked that summer in Hanover, Logic Theorist has become accepted as the first functional artificial intelligence program and the pioneering example of symbolic AI. This school of thought would dominate the field for the next thirty years.
Experiment 2: SHRDLU and Blocks World (1968)
In 2008, CNNMoney asked a selection of global leaders, from Michael Bloomberg to General Petraeus, for the best advice they’d ever received. Larry Page, then President of Google, referred to his Ph.D. program at Stanford. He’d shown the professor advising him “about ten” different topics he was interested in studying, among them the idea of exploring the web’s link structure. The professor purportedly pointed to that topic and said, “Well, that one seems like a really good idea.” That praise would prove a remarkable euphemism; Page’s research would lay the groundwork for Google’s search empire.
The advisor in question was Terry Winograd, a Stanford professor, and AI pioneer. Long before Winograd nudged Page in the direction of a trillion-dollar idea, he created a revolutionary program dubbed “SHRDLU.” Though it looks like the name of a small Welsh town typed with a broken Caps Lock key, SHRDLU was a winking reference to the order of keys on a Linotype machine – the nonsense phrase ETAOIN SHRDLU often appeared in newspapers in error.
Winograd’s program showcased a simulation called “Blocks World”: a closed environment populated with differently colored boxes, blocks, and pyramids. Through natural language queries, users could have the program manipulate the environment, moving various objects to comply with specific instructions. For example, a user could tell SHRDLU to “find a block which is taller than the one you are holding,” or ask whether a “pyramid can be supported by a block.”
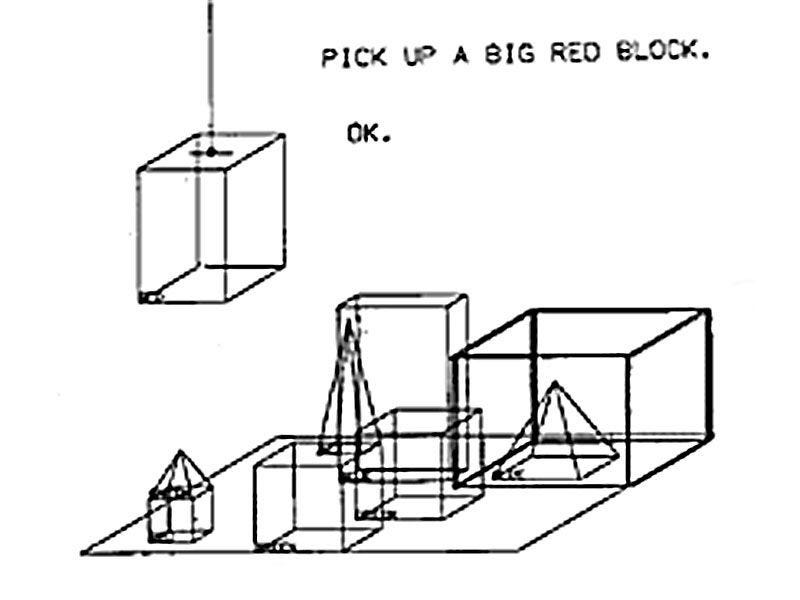
As user dialogues show, SHRDLU understood certain environmental truths: knowing, for example, that two pyramids could not be stacked on top of each other. The program also remembered its previous moves and could learn to refer to certain configurations by particular names.
Critics pointed to SHRDLU’s lack of real-world utility and obvious constraints, given its reliance on a simulated environment. Ultimately, however, SHRDLU proved a critical part of AI’s development. Though still an example of a symbolic approach – the intelligence displayed came about through formalized, logical reasoning rather than emergent behavior – Winograd’s creation showcased impressive new capabilities, with its natural language capabilities particularly notable. The conversational interface SHRDLU used remains ubiquitous today.
Experiment 3: Cyc (1984)
Jorge Luis Borges’s short story, “On Exactitude in Science,” tells the tale of a civilization that makes a map the size of the territory it governs. “[T]he Cartographers Guilds struck a Map of the Empire whose size was that of the Empire, and which coincided point for point with it,” the Argentine literary master writes in his one-paragraph tale.
Cyc is artificial intelligence’s version of the “point for point” map, a project so wildly ambitious it approaches the creation of an entirely novel reality. It has been lauded for its novelty and condemned as “the most notorious failure in AI.”
In 1984, Stanford professor Douglas Lenat set out to solve a persistent problem he saw in the AI programs up to that point: their lack of common sense. The previous decade had been dominated by “expert systems”: programs that relied on human knowledge, inputted via discrete rules, and applied to a narrow scope. For example, in 1972, Stanford started work on a program named MYCIN. By drawing on more than 500 rules, MYCIN could effectively diagnose and treat blood infections, showing “for the first time that AI systems could outperform human experts in important problems.”
While MYCIN and its successors were practical and often impressive, Lenat found them to be little more than the “veneer” of intellect. Sure, these programs knew much about blood disease or legal issues, but what did they understand beyond prescribed confines?
To surpass superficial intelligence, Lenat believed that AI systems needed context. And so, in 1984, with federal support and funding, he set about building Cyc. His plan was deceptively simple and utterly insane: to provide his program with necessary knowledge, Lenat and a team of researchers inputted rules and assertions reflecting consensus reality. That included information across the span of human knowledge from physics to politics, biology to economics. Dictums like “all trees are plants” and “a bat has wings” had to be painstakingly added to Cyc’s knowledge architecture. As of 2016, more than 15 million rules had been inputted.
In Borges’s story, successive generations realize the uselessness of a map the size of the territory. It is discarded in the desert, growing faded and wind-tattered. Nearly forty years after Lenat set to work on the project, Cyc has yet to justify the hundreds of millions of investment and cumulative thousands of years of human effort it has absorbed. Though Cyc’s technology does seem to have been used by real-world stakeholders, experiments over the years have shown its knowledge is patchy, undermining its utility. In the meantime, newer architectures and approaches have delivered better results than Lenat’s more gradual approach.
Ultimately, Cyc’s greatest contribution to the development of AI was its failure. Despite Lenat’s brilliance and boldness, and the commitment of public and private sector stakeholders, it has failed to break out. In doing so, it revealed the limitations of “expert systems” and knowledge-based AI.
Experiment 4: “Elephants Don’t Play Chess” (1990)
The dream of intelligence has often intersected with robotics. It is not enough to have a brain in the abstract, floating in the ether. For brilliance to have an impact, it requires a body.
Beginning in the mid-1980s, a school of rebel researchers emerged, arguing for the importance of “embodied” AI. Led by Australian Rodney Brooks, this group contended that logic-driven, symbolic AI advocates of the past misunderstood intelligence; humans and other animals don’t navigate life by relying on assiduously inputted rules; they do so by interacting and learning from their environments. If AI programs were to become useful, they needed to be “situated in the real world.”
Brooks’ 1990 paper “Elephants Don’t Play Chess” distilled the ideas of this new “behavioral AI” movement and chronicled the then-MIT professor’s robotics experiments. As well as outlining the achievements of scurrying robots like “Allen” and “Herbert” (a nice nod to Logic Theorist’s founders), Brooks articulated a new structure for AI programs. In simple terms, Brooks’ “subsumption architecture” splits a robot’s desired actions into discrete behaviors such as “avoiding obstacles” and “wandering around.” It then orders those actions into an architecture with the most fundamental imperatives at the base. A robot with this kind of architecture, for example, would prioritize avoiding obstacles first and foremost, moving up the stack to broader exploration.
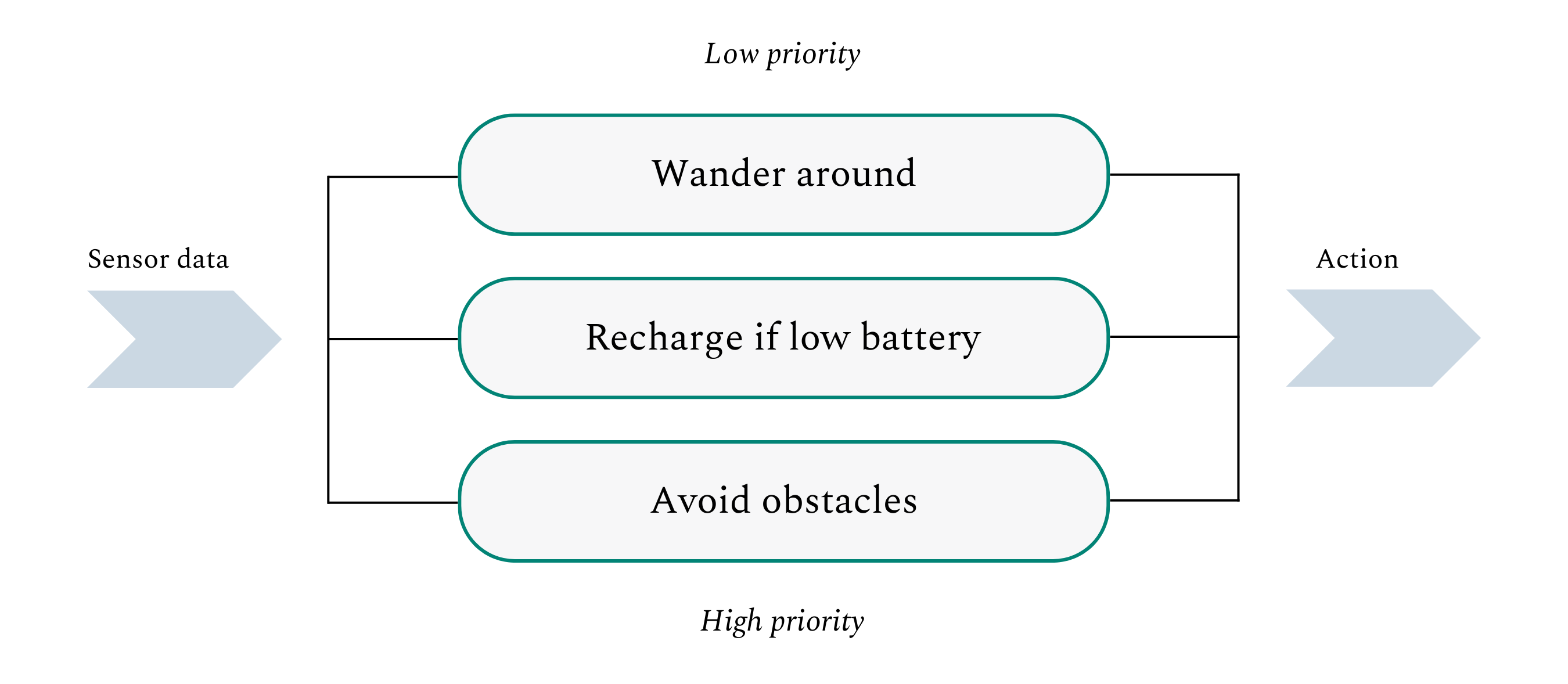
Brooks’ belief that behavioral AI would likely have real utility was eventually borne out. The same year that he published his paper, Brooks and two MIT colleagues founded iRobot. Twelve years later, in 2002, the company released its now-flagship product, the Roomba. Though no one would consider the Roomba a thinking machine, the wildly popular automated vacuum cleaner is a clear example of how Brooks’ embodied techniques can deliver practical benefits.
Experiment 5: AlexNet (2012)
In 1931, A Hundred Authors Against Einstein was published. In it, dozens of academics attempted to poke holes in the German physicist’s theories. In response to its publication, Einstein is said to have quipped, “If I were wrong, then one would have been enough!”
For much of his career, Geoff Hinton has been required to take a similarly defiant stance against naysayers. Starting in the 1970s, the British researcher set out to understand and emulate the brain’s structure with technology. Unlike the symbolic or behavioral AI camps, Hinton was part of a small, unfashionable group of researchers that believed true intelligence wouldn’t stem from logical frameworks, vast compendiums of rules, or environmental interactions. Instead, it would come from replicating the brain’s structure and functionality, creating “artificial neural networks,” better known as “neural nets.”
In simple terms, these networks act as our brains do: various inputs lead to neurons firing, which produce certain outputs. In a traditional neural net, neurons or “units” are arranged in layers that “feed forward,” meaning that outputs from the previous layer are received by the following one. Each unit in this network performs some kind of important computational activity: like recognizing part of an image so that it can eventually identify what’s in it.
Hinton was not the first researcher to see promise in this idea. Indeed, in 1958, just two years after the historic Dartmouth workshop, Cornell academic Frank Rosenblatt constructed a “perceptron” machine – essentially a primitive version of neural nets. Arguably, interest in the technique predates even Rosenblatt’s work, with researchers in the 1940s constructing “neurons” with electrical circuits.
However, while others contributed to the field, Hinton pushed it forward, despite the opposition of many in the AI community who considered it a waste of time. “Geoff was one of only a handful of people on the planet that was pursuing this technology,” business journalist Ashlee Vance said of Hinton’s research into neural nets. “He would show up at academic conferences and be banished to the back rooms. He was treated as really a pariah.”
Despite that poor treatment, Hinton never lost faith in the merits of his ideas: “It was just obvious to me that this was the right way to go. The brain is a big neural network, so it has to be that stuff like this can work because it works in our brains.” As money and attention were poured into knowledge-based systems like Cyc, Hinton conducted pioneering work, such as his seminal 1986 paper on “backpropagation,” a training algorithm for neural nets.
Insufficient data and limited computing power traditionally hamstrung neural nets and other machine learning techniques. Starting around 2005, the tide began to change. Faster chips became available, and researchers could use greater quantities of data. The momentum solidified around a revised concept named “deep learning.” As opposed to traditional neural nets, “deep learning” networks were more powerful in three critical ways:
More layers. Different layers are used to conduct different types of processing, with complexity increasing as you approach the output. By adding more layers, more difficult processing became available.
More units. In the 1990s, neural nets contained approximately 100 units, constraining their capabilities. Deep learning networks were orders of magnitude larger, hitting around 1 million units by 2016.
More connections. Along with more layers and units, the deep learning movement created neural nets with more connections. Again, this increased their abilities significantly.
“AlexNet” represented a turning point for deep learning and a coronation of Hinton’s ideas. In 2012, two students of Hinton’s, Alex Krizhevsky and Ilya Sutskever, created an algorithm to compete in the ImageNet Challenge. Founded by Fei-Fei Li in 2009, ImageNet is a foundational database with over 14 million tagged pictures. It is used to train AI image-recognition models: the idea is that if you show a program enough pictures and tell it what is represented, it can learn to label new, untagged images accurately.

To test the capabilities of image-recognition programs, ImageNet hosted an annual competition in which different teams vied to produce the most accurate model. In 2010, the best-performing program had a 72% accuracy rate; in 2011, it crept forward to 75%. Both were far below the average human performance of 95%.
In preparation for the 2012 contest, AlexNet’s team took an alternative approach, creating a deep learning network powered by GPUs. These more powerful processors allowed Alex Krizhevsky and Ilya Sutskever to train their complex, multi-layered network efficiently. Though this may sound de rigueur today, AlexNet’s team’s choices were unorthodox at the time.
The results were striking. At the ImageNet Challenge, AlexNet blew its competition out of the water, achieving an 85% accuracy rate. Crucially, it outperformed all other algorithms by more than 10%. In the following years, programs inspired by AlexNet would blow past the human threshold.
More than its capabilities, AlexNet represented a turning point for AI. The future would be made by architecting deep networks powered by GPUs and trained on vast quantities of data.
Experiment 6: “Playing Atari with Deep Reinforcement Learning” (2013)
AI has a long, storied connection with games. In 1950, legendary mathematician Claude Shannon penned a study called “Programming a Computer for Playing Chess,” which outlined techniques and algorithms to create a talented chess machine. Of course, less than fifty years later, IBM introduced Deep Blue, the first AI program that beat a world champion under regulation conditions. Its defeat of Garry Kasparov on February 10, 1996 – the first of several – demonstrated AI’s ability to outmatch humans in even highly complex, theoretically cerebral challenges, attracting major attention.
In 2013, a new game-playing AI was introduced to the world, albeit with significantly less fanfare. That year, Cambridge-based company DeepMind enunciated its goal to create a “single neural network” capable of playing dozens of Atari video game titles. In itself, that might not have been a particularly audacious mission. What made DeepMind’s work so intriguing to experts like Michael Wooldridge was the methodology the firm used. As explained in the Oxford professor’s book, A Brief History of Artificial Intelligence, “Nobody told the program anything at all about the games it was playing.” Researchers did not attempt to feed its engine certain rules or the tactics gleaned from a champion player. The program simply played the game and observed which actions increased its score.

This process is called “reinforcement learning.” Rather than relying on training data, reinforcement learning programs learn through “rewards.” When the program does something good (oriented toward its goal), it receives a positive reward. If it does something negative (counter to its goal), it receives a negative one. Through this iterative feedback process, a program learns to reach its goal. Because it doesn’t receive explicit instructions, it often wins by employing strategies a human might never have conceived of – and may not fully understand.
The results of DeepMind’s Atari program were a revelation. A 2015 paper revealed that the engine had learned to outperform humans at 29 of the 49 Atari titles initially outlined. In some instances, the program reached “superhuman” levels and demonstrated intelligent, novel techniques.
Though impressive in its own right, the work DeepMind did with its Atari program set the groundwork for later innovations. In 2016, the company released AlphaGo, an AI designed to play the Chinese game Go – a vaster, significantly more complex game than chess. “Shannon’s number,” named after the information theory pioneer, pegs the number of possible moves in a chess game at 10123; Go’s is 10360. Using a mixture of “supervised learning” (feeding the algorithm game information from expert players) and reinforcement learning, DeepMind created an engine that comfortably defeated world champion Lee Sedol four games to one, relying on techniques and tactics that look strange to the human player. AlphaGo’s success was followed by broader and more powerful programs like AlphaGo Zero and AlphaZero. The latter learned to play high-level chess in just nine hours, learning only by playing itself.
DeepMind’s crowning achievement was AlphaFold. For fifty years, the “protein folding problem” – figuring out what three-dimensional shapes proteins form – had stood as an unsolved biological “grand challenge.”
By relying on reinforcement learning and other techniques, AlphaFold radically improved protein modeling accuracy from approximately 40% to 85%. As outlined in The Age of AI, AlphaFold’s impact is profound, “enabling biologists and chemists around the world to revisit old questions they had been unable to answer and to ask new questions about battling pathogens in people, animals, and plants.”
DeepMind demonstrated new methods for AI development that created programs that far exceeded human capabilities, whether in playing video games or mapping biological structures.
Experiment 7: “Attention is All You Need” (2017)
Not very long ago, AI was rather poor at natural language creation. Sure, early applications like SHRDLU demonstrated some ability, but by and large, the ability to comprehend and write developed more slowly than other skills. By the mid-1990s, AI could crush legendary grand masters like Kasparov, but it wouldn’t have been able to craft a paragraph describing its feat. Even as late as 2015, language abilities lagged far behind deep learning models’ numinous abilities in image recognition and game-playing.
“Attention is All You Need” marked a turning point. The 2017 paper introduced the “transformer,” a novel architecture that relied on a process called “attention.” At the highest level, a transformer pays “attention” to all of its inputs simultaneously and uses them to predict the optimal output. By paying attention in this way, transformers can understand context and meaning much better than previous models.
Let’s work through a basic example of this principle. If you provided a prompt like “describe a palm tree” to a traditional model, it might struggle. It would look to process each word individually and wouldn’t note their connection to one another. You can imagine how that might result in obvious errors. For one thing, the term “palm” has multiple meanings: it refers to a type of tree and the underside of a hand. A model that doesn’t recognize the proximity of “tree” to “palm” could easily wax rhapsodic about love and life lines before veering into a discussion of the mighty oak.
By recognizing and encoding context, transformers were able to vastly improve text prediction, laying the groundwork for vastly superior conversational AIs like GPT-4 and Claude. Interestingly, transformers may emulate the brain more than we initially realized – once again validating Hinton’s hunches. Recent research suggests that the hippocampus, critical to memory function, is a “transformer, in disguise.” It represents another step forward in AI’s quest to manifest a general intelligence that meets, and eventually fully exceeds, our own.
If you’re interested in further exploring the history of AI, I found the following books useful and enjoyable: The Age of AI by Eric Schmidt, Henry Kissinger, and Daniel Huttenlocher; A Brief History of Artificial Intelligence by Michael Wooldridge; and Machines Who Think by Pamela McCorduck.
The Generalist’s work is provided for informational purposes only and should not be construed as legal, business, investment, or tax advice. You should always do your own research and consult advisors on these subjects. Our work may feature entities in which Generalist Capital, LLC or the author has invested.